CARGO UI
Full project description Interactive Prototype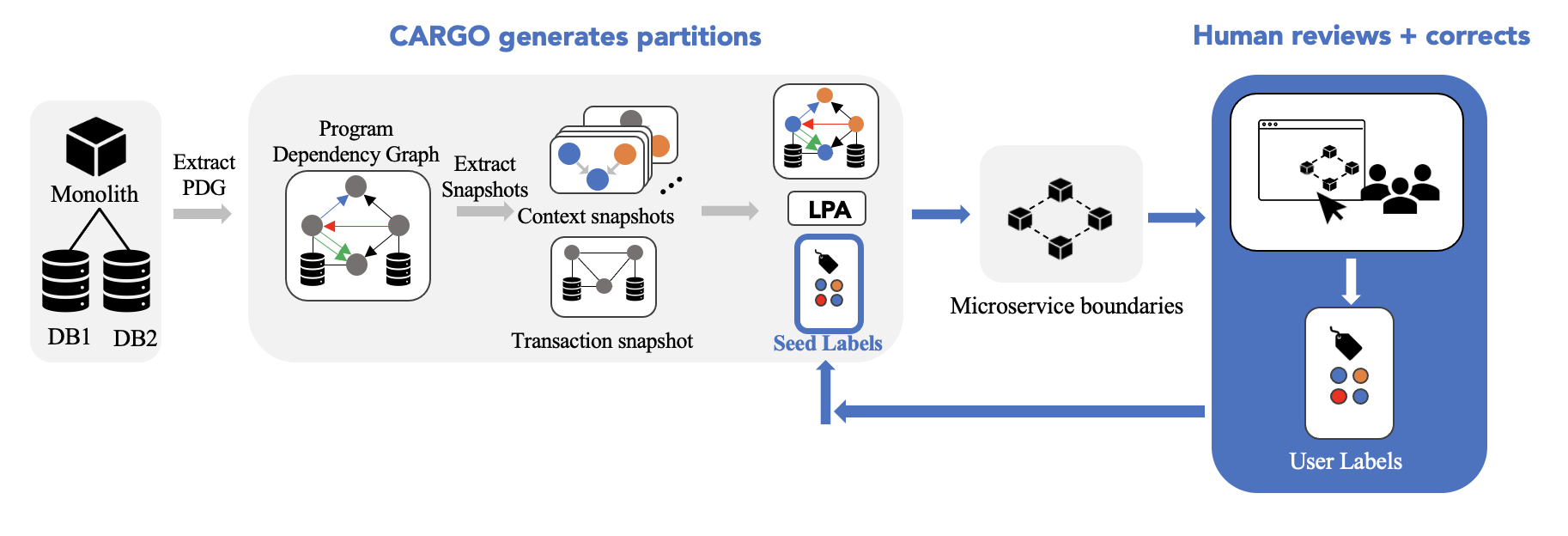
An essential component of application modernization is the decomposition of monolith architectures to microservices, which has become a standard for designing enterprise applications. Various recommendation tools have been developed to facilitate this task but they may produce inaccuracies or suggestions that misalign with developers’ intentions. I conducted remote interviews with 8 software engineers responsible for microservice development in some capacity that sparked discussions about information overload, the importance of communicating uncertainty and opportunities for human-AI collaboration in microservice developement tools. Based on these insights, I implemented and evaluated an interactive UI that supports code partitioning using a human-in-the-loop framework. Evaluative interviews revealed improved usability, transparency and comprehension.
In order to better understand current workflow and pain points with current microservice recommendation tools, we conducted formative interviews with 8 software engineers responsible for microservice development or managing teams that develop microservices at an enterprise level. The questions spanned the following themes: expert role and tasks, experience with refactoring, experience with tool features and interactions, opinions on an ideal microservice tool. We expanded on the level of detail they desired when partitioning code, the UI interactions and features. Two of the authors conducted a thematic analysis, consisting of identifying, annotating and extracting common responses and themes from the interviews. We reviewed meeting recordings and transcripts and identified high-level themes, and refined them through collaborative discussions. We summarize our main insights in this section.
Information Overload
A prominent topic that was brought up by participants is the issue of information overload, especially for large applications. P6 mentioned that their application "had a lot of classes and it was hard to figure out what was going on". P3 mentioned that the size of the application is an important contributor to the information overload problem "If you have a three microservice application, it’s consumable, but when you have like a fifty or, you know, sixty it starts to get really confusing. So having more summary pages, you know, have things in red like problem here, green here, you know". They also brought up the usefulness of filtering several components of the view, such as the edge types and edge weights. P1 and P2 mentioned the usefulness of the table view and they can more easily find a class compared to the graph view, where they have to hover over each node. P2 stated that "In the table view, I can search for a class more easily but in the graph view, I have to hover over every node to find a class". The topic of information overload has been extensively studied in the visualization community. One of the most influential mantra by Schneiderman is "overview first, zoom and filter, details on demand".
Customization and granularity
We asked users questions about the level of granularity at which they would prefer to see their application. One theme that was brought up was the importance of database interactions, which is at the center of the CARGO algorithm. P4 stated that "you can have a really good microservice design but it can all fall apart if you don’t design how you interact with the database correctly". In their current application, users can see their applications in the form of classes. When addressing our question about the desired level of granularity, responses varied. However, it is important to highlight the interplay between desired level of granularity and the information overload issue. Several participants P2 mentioned that "for my application, classes are granular enough. Showing methods would be too messy". They highlighted that the user perhaps could opt into seeing method as long as they don’t overcrowd the display. P3 mentioned that "Seeing methods would be useful as long as it’s kind of like look here in this class, there’s some problems in here and then you can open it up. See where the problems are like, it allows you to drill down, but let people opt into that complexity". We posit that the desired level of granularity depends on several factors including the size of the application, level of familiarity with the application and experience of the developer. Prior work highlights the potential benefit of creating partitions at the function level [16].
Considerations for Explainability
This line of questioning was highly influenced by Weisz et al. [ 22 ], who inquired about developers acceptance and utility of imperfect AI. While different microservice recommendation tools employ different clustering strategies, most of them including their current industry tool are deterministic. Moreover, the current microservice tool does not provide the user with meaningful partition names based on its strategy. Therefore, we asked participants to comment on the importance and utility three aspects of microservice recommendation: (1) communicating uncertainty, (2) meaningful partition names and description and (3) comprehension of AI mechanics. In general, participants were enthusiastic about a system that shows classification confidence. As stated by P1 "showing uncertainty for classes would be useful cause you can just ignore some and focus on the borderline cases". Similarly, P4 mentioned the importance of indicating where there is a problem in the partitioning. P2 mentioned that "If you could say you are partitioning this together because they are part of this functionality, and then give me a short explanation of what it is, I think that would be very useful". When it comes to the importance of assigning meaningful partition names and definition, once again we found that responses varied based on the size and the developer’s familiarity with the application. While P1 mentioned that he is so familiar with his application that he can just glance at a partition and tell which business use case it represents, other users stated that it would be a very useful feature. P2 mentioned "It would be very useful to see partition name and description. It would help me understand why they put some classes in this partition." Users considered the comprehension of AI mechanics to be unnecessary and potentially confusing.
Motivated by our design considerations, we evaluated our prototype with the same eight software engineers who completed the formative interviews. We conducted 30-minute guided user studies studies via videocall that we recorded. In our study, users were asked to complete a set of pre-defined tasks while using a think-aloud protocol. When conducting these tasks, we focus on evaluating the features described in our design considerations based on how participants understand, use and interact with them.
Study Design
Our scenario used the DayTrader application, a popular Java Enterprise Edition (JEE) trading application 1, with partition assignments generated by CARGO [ 17 ]. First, we briefly instructed users on the think-aloud protocol and gave an overview of the task. Then, we shared a link to our instruction page and asked them to share their screens. The instruction page explained each feature in our interface and their functionality. They were then shown the following lists of tasks.
Tasks (1), (2), (3) and (4) evaluate the use of the edge filters and class search features. We observe whether user interactions appear to be intuitive and seamless. In task (5), we observe whether users make use of the uncertainty information available to them through the node opacity. In task (6) and (7), we test how the users understand and interact with the partition suggestions the usability of our approach for splitting a class into two classes. In tasks (8) and (9), we observe how the user expands and collapse a class and whether they are able to differentiate methods from classes. In (10), we observe how users split a class into two classes. After reading the instructions and tasks, participants clicked on a button to launch the interface in a new tab. Participants conducted the tasks sequentially, asking for guidance when needed while we took notes of our observations
Findings
When evaluating our prototype, users responded positively to the several functionalities provided by the features implemented. Notably, they highlighted the importance of the ability to explore methods and their partitions, and the ability to receive partitioning recommendations. When it comes to the interpretability and usability of the features, all users correctly interpreted the class uncertainty and were able to scan the display to detect low confidence nodes and split a class. When graphically expanding classes to methods, while users correctly performed the interaction and correctly interpreted the smaller circles as methods, they missed one method that was part of another partition and less salient. We found that users did not understand partition suggestions, but instead thought that it was a confirmation of their changes. Many studies have found that people tend to misunderstand or ignore suggestions presented to them while they are conducting a task [14 ].
Future work needs to examine ways to integrate other important features and examine how to present suggestions to strike the right balance between encouraging their use while minimizing intrusion. Nonetheless, our work provides valuable insights into how users interact with various UI components in a mixed-initiative microservice recommendation tool.
[1] Firas Al-Doghman, Nour Moustafa, Ibrahim Khalil, Zahir Tari, and Albert Zomaya. 2022. AI-enabled secure microservices in edge computing:
Opportunities and challenges. IEEE Transactions on Services Computing (2022).
[2] Zahra Ashktorab, Michael Desmond, Josh Andres, Michael Muller, Narendra Nath Joshi, Michelle Brachman, Aabhas Sharma, Kristina Brimijoin,
Qian Pan, Christine T Wolf, et al . 2021. Ai-assisted human labeling: Batching for efficiency without overreliance. Proceedings of the ACM on
Human-Computer Interaction 5, CSCW1 (2021), 1–27.
[3] Gagan Bansal, Besmira Nushi, Ece Kamar, Eric Horvitz, and Daniel S Weld. 2021. Is the most accurate ai the best teammate? optimizing ai for
teamwork. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 11405–11414.
[4] Leilani Battle, Remco Chang, and Michael Stonebraker. 2016. Dynamic prefetching of data tiles for interactive visualization. In Proceedings of the
2016 International Conference on Management of Data. 1363–1375.
[5] Eli T Brown, Alvitta Ottley, Helen Zhao, Quan Lin, Richard Souvenir, Alex Endert, and Remco Chang. 2014. Finding waldo: Learning about users
from their interactions. IEEE Transactions on visualization and computer graphics 20, 12 (2014), 1663–1672.
[6] R Jordon Crouser and Remco Chang. 2012. An affordance-based framework for human computation and human-computer collaboration. IEEE
Transactions on Visualization and Computer Graphics 18, 12 (2012), 2859–2868.
[7] Filip Dabek and Jesus J Caban. 2016. A grammar-based approach for modeling user interactions and generating suggestions during the data
exploration process. IEEE transactions on visualization and computer graphics 23, 1 (2016), 41–50.
[8] Alex Endert, Patrick Fiaux, and Chris North. 2012. Semantic interaction for visual text analytics. In Proceedings of the SIGCHI conference on Human
factors in computing systems. 473–482.
[9] Chen-Yuan Fan and Shang-Pin Ma. 2017. Migrating monolithic mobile application to microservice architecture: An experiment report. In 2017 ieee
international conference on ai & mobile services (aims). IEEE, 109–112.
[10] Kevin Hu, Diana Orghian, and César Hidalgo. 2018. DIVE: A mixed-initiative system supporting integrated data exploration workflows. In Proceedings
of the workshop on human-in-the-loop data analytics. 1–7.
[11] Anup K Kalia, Jin Xiao, Rahul Krishna, Saurabh Sinha, Maja Vukovic, and Debasish Banerjee. 2021. Mono2micro: a practical and effective tool for
decomposing monolithic java applications to microservices. In Proceedings of the 29th ACM joint meeting on European software engineering conference
and symposium on the foundations of software engineering. 1214–1224.
[12] Hannah Kim, Dongjin Choi, Barry Drake, Alex Endert, and Haesun Park. 2019. TopicSifter: Interactive search space reduction through targeted
topic modeling. In 2019 IEEE Conference on Visual Analytics Science and Technology (VAST). IEEE, 35–45.
[13] Lisa J Kirby, Evelien Boerstra, Zachary JC Anderson, and Julia Rubin. 2021. Weighing the evidence: On relationship types in microservice extraction.
In 2021 IEEE/ACM 29th International Conference on Program Comprehension (ICPC). IEEE, 358–368.
[14] Shayan Monadjemi, Mengtian Guo, David Gotz, Roman Garnett, and Alvitta Ottley. 2023. Human-Computer Collaboration for Visual Analytics: an
Agent-based Framework. arXiv preprint arXiv:2304.09415 (2023).
[15] Shayan Monadjemi, Sunwoo Ha, Quan Nguyen, Henry Chai, Roman Garnett, and Alvitta Ottley. 2022. Guided Data Discovery in Interactive
Visualizations via Active Search. In 2022 IEEE Visualization and Visual Analytics (VIS). IEEE, 70–74.
[16] Rina Nakazawa, Takanori Ueda, Miki Enoki, and Hiroshi Horii. 2018. Visualization tool for designing microservices with the monolith-first approach.
In 2018 IEEE Working Conference on Software Visualization (VISSOFT). IEEE, 32–42.
[17] Vikram Nitin, Shubhi Asthana, Baishakhi Ray, and Rahul Krishna. 2022. CARGO: ai-guided dependency analysis for migrating monolithic applications
to microservices architecture. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 1–12.
[18] Alvitta Ottley, Roman Garnett, and Ran Wan. 2019. Follow the clicks: Learning and anticipating mouse interactions during exploratory data analysis.
In Computer Graphics Forum, Vol. 38. Wiley Online Library, 41–52.
[19] Francisco Ponce, Gastón Márquez, and Hernán Astudillo. 2019. Migrating from monolithic architecture to microservices: A Rapid Review. In 2019
38th International Conference of the Chilean Computer Science Society (SCCC). IEEE, 1–7.
[20] Jiao Sun, Q Vera Liao, Michael Muller, Mayank Agarwal, Stephanie Houde, Kartik Talamadupula, and Justin D Weisz. 2022. Investigating explainability
of generative AI for code through scenario-based design. In 27th International Conference on Intelligent User Interfaces. 212–228.
[21] Yingying Wang, Harshavardhan Kadiyala, and Julia Rubin. 2021. Promises and challenges of microservices: an exploratory study. Empirical Software
Engineering 26, 4 (2021), 63.
[22] Justin D Weisz, Michael Muller, Stephanie Houde, John Richards, Steven I Ross, Fernando Martinez, Mayank Agarwal, and Kartik Talamadupula.
2021. Perfection not required? Human-AI partnerships in code translation. In 26th International Conference on Intelligent User Interfaces. 402–412.
[23] Justin D Weisz, Michael Muller, Steven I Ross, Fernando Martinez, Stephanie Houde, Mayank Agarwal, Kartik Talamadupula, and John T Richards.
2022. Better together? an evaluation of ai-supported code translation. In 27th International Conference on Intelligent User Interfaces. 369–391.
[24] Brian Whitworth. 2005. Polite computing. Behaviour & Information Technology 24, 5 (2005), 353–363.